Continuous Integration and Pipelines
In this lab you will learn about pipelines and how to configure a pipeline in OpenShift so that it will take care of the application lifecycle.
A continuous delivery (CD) pipeline is an automated expression of your process for getting software from version control right through to your users and customers. Every change to your software (committed in source control) goes through a complex process on its way to being released. This process involves building the software in a reliable and repeatable manner, as well as progressing the built software (called a "build") through multiple stages of testing and deployment.
OpenShift Pipelines is a cloud-native, continuous integration and delivery (CI/CD) solution for building pipelines using Tekton. Tekton is a flexible, Kubernetes-native, open-source CI/CD framework that enables automating deployments across multiple platforms (Kubernetes, serverless, VMs, etc) by abstracting away the underlying details.
Understanding Tekton
Tekton defines a number of Kubernetes custom resources as building blocks in order to standardize pipeline concepts and provide a terminology that is consistent across CI/CD solutions.
The custom resources needed to define a pipeline are listed below:
-
Task: a reusable, loosely coupled number of steps that perform a specific task (e.g. building a container image) -
Pipeline: the definition of the pipeline and theTasksthat it should perform -
TaskRun: the execution and result of running an instance of task -
PipelineRun: the execution and result of running an instance of pipeline, which includes a number ofTaskRuns
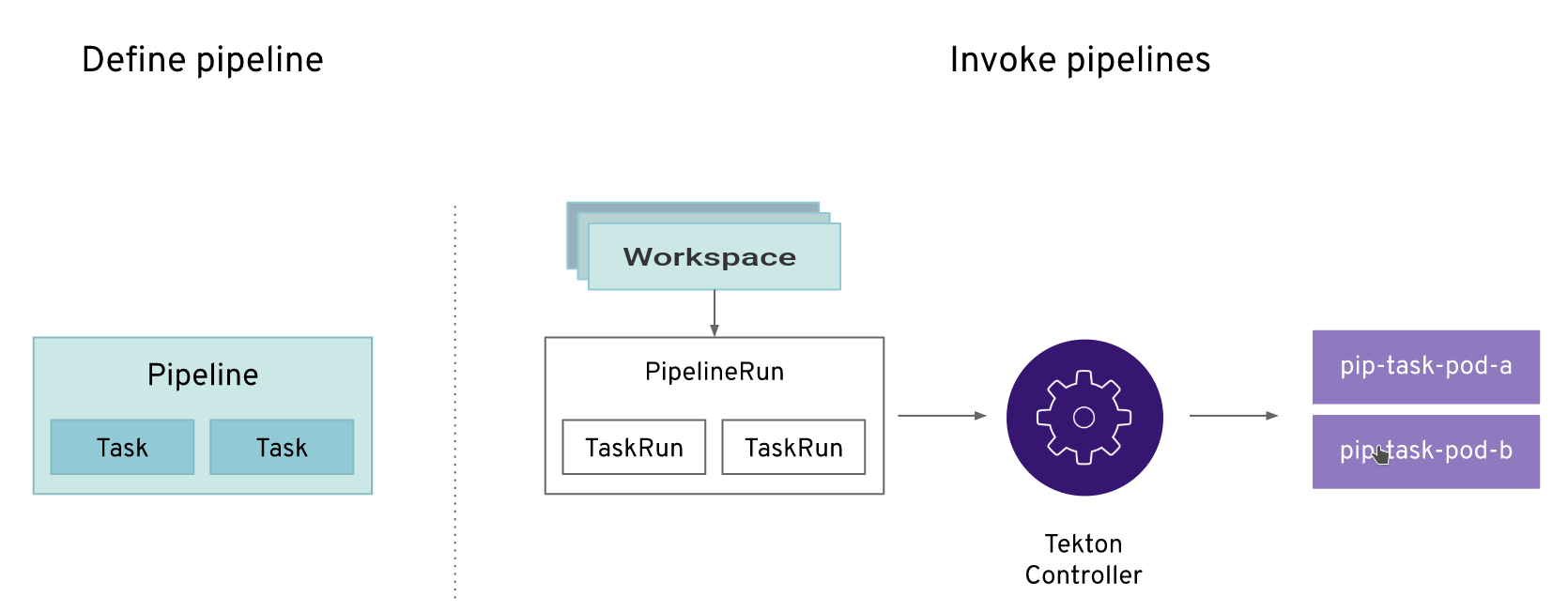
In short, in order to create a pipeline, one does the following:
-
Create custom or install existing reusable
Tasks -
Create a
PipelineandPipelineResourcesto define your application’s delivery pipeline -
Create a
PersistentVolumeClaimto provide the volume/filesystem for pipeline execution or provide aVolumeClaimTemplatewhich creates aPersistentVolumeClaim -
Create a
PipelineRunto instantiate and invoke the pipeline
For further details on pipeline concepts, refer to the Tekton documentation that provides an excellent guide for understanding various parameters and attributes available for defining pipelines.
Set Up Your Pipeline
| Ensure you met all Prerequisites before proceeding. OpenShift Pipelines installed in your cluster and a GitHub account are required. |
A deployment configuration in OpenShift can contain Triggers, which tells OpenShift to automatically redeploy the pod whenever a new image is built for that service or configuration changes.
As we want the Tekton pipeline to control when builds and deployments happen, we need to disable the ability on the current Deployment to automatically trigger when there is a new image or a configuration change.
Configure Manual Deployments on Dev Application
DeploymentConfigs have triggers that allow automatic deploying when a new image has been pushed into OpenShift Registry. In this case we want the Pipeline to drive the flow of updating the Application, thus we just need to disable those triggers for the moment:
oc set triggers dc nationalparks --manual -n workshopYou should get an output like this:
deploymentconfig.apps.openshift.io/nationalparks triggers updatedCreate Your Pipeline
As pipelines provide the ability to promote applications between different stages of the delivery cycle, Tekton, which is our Continuous Integration server that will execute our pipelines, will be deployed on a project with a Continuous Integration role. Pipelines executed in this project will have permissions to interact with all the projects modeling the different stages of our delivery cycle.
For this example, we’re going to deploy our pipeline which is stored in the same GitHub repository where we have our code. In a more real scenario, and in order to honor infrastructure as code principles, we would store all the pipeline definitions along with every OpenShift resources definitions we would use.
Let’s create now a Tekton pipeline for Nationalparks backend, select your OpenShift cluster type from below table:
oc create -f https://raw.githubusercontent.com/openshift-roadshow/nationalparks/master/pipeline/nationalparks-pipeline-all-vfs.yaml -n workshopoc create -f https://raw.githubusercontent.com/openshift-roadshow/nationalparks/master/pipeline/nationalparks-pipeline-all.yaml -n workshopVerify the Tasks you created:
oc get tasks -n workshopYou should see something similar:
NAME AGE
redeploy 13s
s2i-java-11-binary 13sVerify the Pipeline you created:
oc get pipelines -n workshopYou should see something like this:
NAME AGE
nationalparks-pipeline 8sNow let’s review our Tekton Pipeline:
---
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: nationalparks-pipeline
spec:
params:
- default: nationalparks
description: The application name
name: APP_NAME
type: string
- default: 'https://github.com/openshift-roadshow/nationalparks.git'
description: The application git repository url
name: APP_GIT_URL
type: string
- default: master
description: The application git repository revision
name: APP_GIT_REVISION
type: string
tasks:
- name: git-clone
params:
- name: url
value: $(params.APP_GIT_URL)
- name: revision
value: $(params.APP_GIT_REVISION)
- name: submodules
value: 'true'
- name: depth
value: '1'
- name: sslVerify
value: 'true'
- name: deleteExisting
value: 'true'
taskRef:
kind: ClusterTask
name: git-clone
workspaces:
- name: output
workspace: app-source
- name: build-and-test
params:
- name: GOALS
value:
- package
- name: PROXY_PROTOCOL
value: http
runAfter:
- git-clone
taskRef:
kind: ClusterTask
name: maven
workspaces:
- name: source
workspace: app-source
- name: maven-settings
workspace: maven-settings
- name: build-image
params:
- name: PATH_CONTEXT
value: .
- name: TLSVERIFY
value: 'false'
- name: OUTPUT_IMAGE_STREAM
value: '$(params.APP_NAME):latest'
runAfter:
- build-and-test
taskRef:
kind: Task
name: s2i-java-11-binary
workspaces:
- name: source
workspace: app-source
- name: redeploy
params:
- name: DEPLOYMENT_CONFIG
value: $(params.APP_NAME)
runAfter:
- build-image
taskRef:
kind: Task
name: redeploy
workspaces:
- name: app-source
- name: maven-settingsA Pipeline is a user-defined model of a CD pipeline. A Pipeline’s code defines your entire build process, which typically includes stages for building an application, testing it and then delivering it.
A Task and a ClusterTask contain some step to be executed. ClusterTasks are available to all user within a cluster where OpenShift Pipelines has been installed, while Tasks can be custom.
This pipeline has 4 Tasks defined:
-
git clone: this is a
ClusterTaskthat will clone our source repository for nationalparks and store it to aWorkspaceapp-sourcewhich will use the PVC created for itapp-source-workspace -
build-and-test: will build and test our Java application using
mavenClusterTask -
build-image: will build an image using a binary file as input in OpenShift. The build will use the .jar file that was created and a custom Task for it
s2i-java11-binary -
redeploy: it will deploy the created image on OpenShift using the DeploymentConfig named
nationalparkswe created in the previous lab, using the custom Taskredeploy
From left-side menu, click on Pipeline, then click on nationalparks-pipeline to see the pipeline you just created.
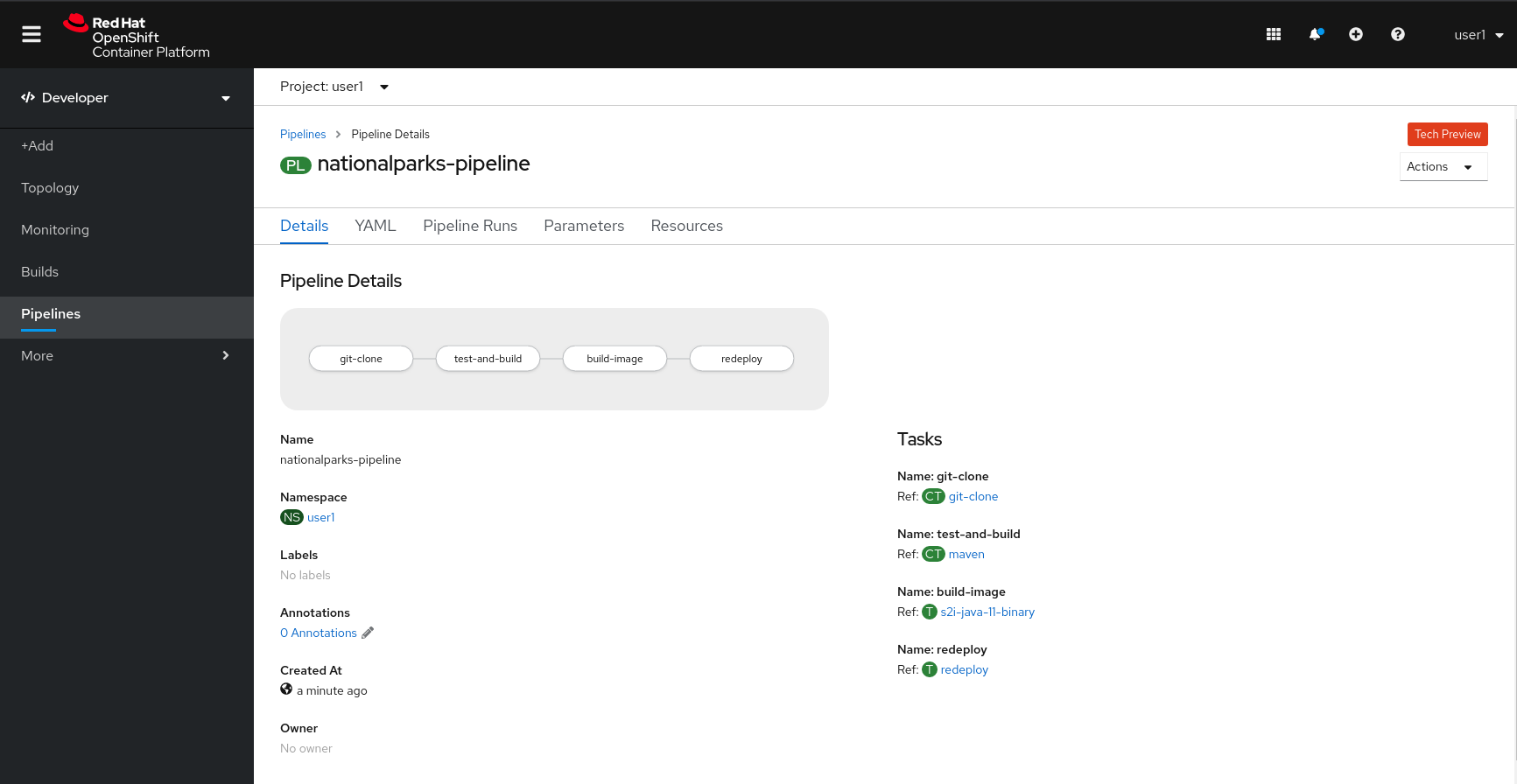
The Pipeline is parametric, with default value on the one we need to use.
It is using two Workspace:
-
app-source: linked to a PersistentVolumeClaim
app-source-pvccreated from the YAML template we used in previous command. This will be used to store the artifact to be used in different Task -
maven-settings: an EmptyDir volume for the maven cache, this can be extended also with a PVC to make subsequent Maven builds faster
Run the Pipeline
Select your OpenShift cluster type and follow instruction to start the pipeline:
oc create -f https://raw.githubusercontent.com/openshift-roadshow/nationalparks/master/pipeline/nationalparks-pipelinerun.yaml -n workshopTo start it with Web Console, within Developer Perspective go to left-side menu, click on Pipeline, then click on nationalparks-pipeline. From top-right Actions list, click on Start.
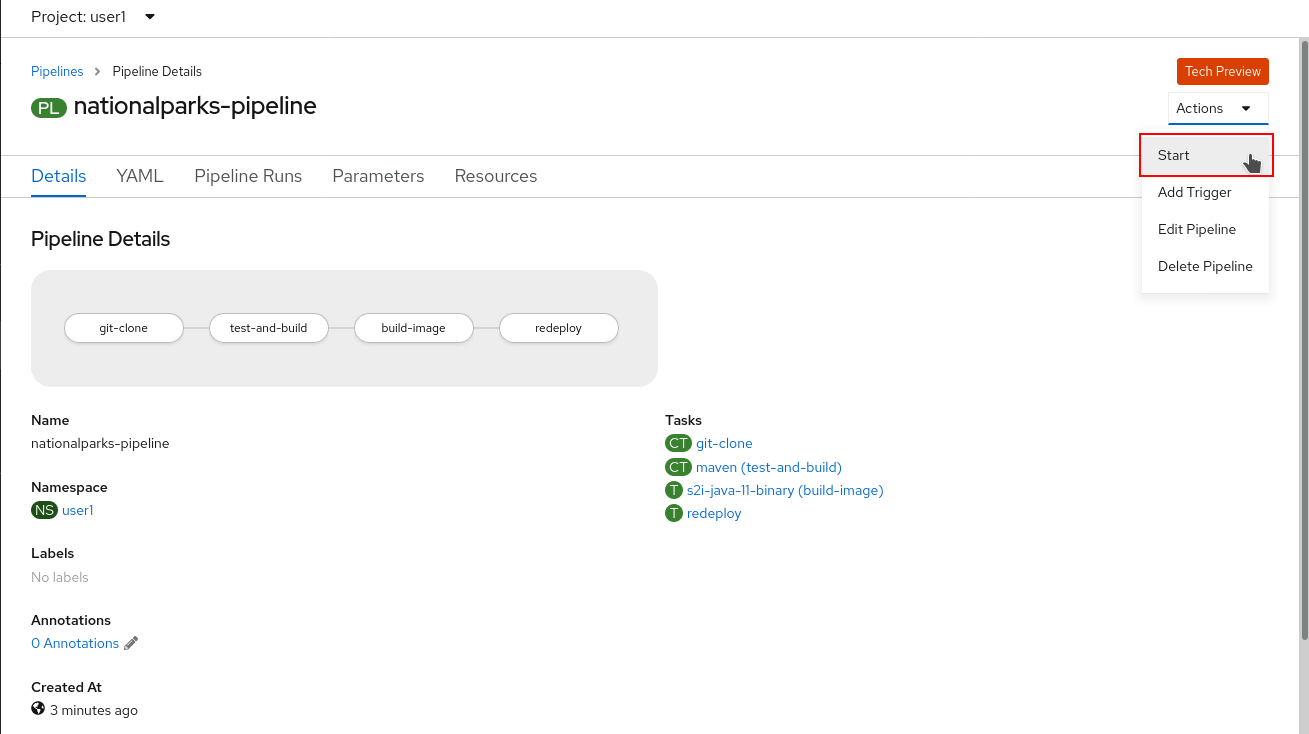
You will be prompted with parameters to add the Pipeline, showing default ones.
In APP_GIT_URL, verify the nationalparks repository from GitHub:
https://github.com/openshift-roadshow/nationalparks.gitIn Workspaces→ app-source select PVC from the list, then select app-source-pvc. This is the share volume used by Pipeline Tasks in your Pipeline containing the source code and compiled artifacts.
Click on Start to run your Pipeline.
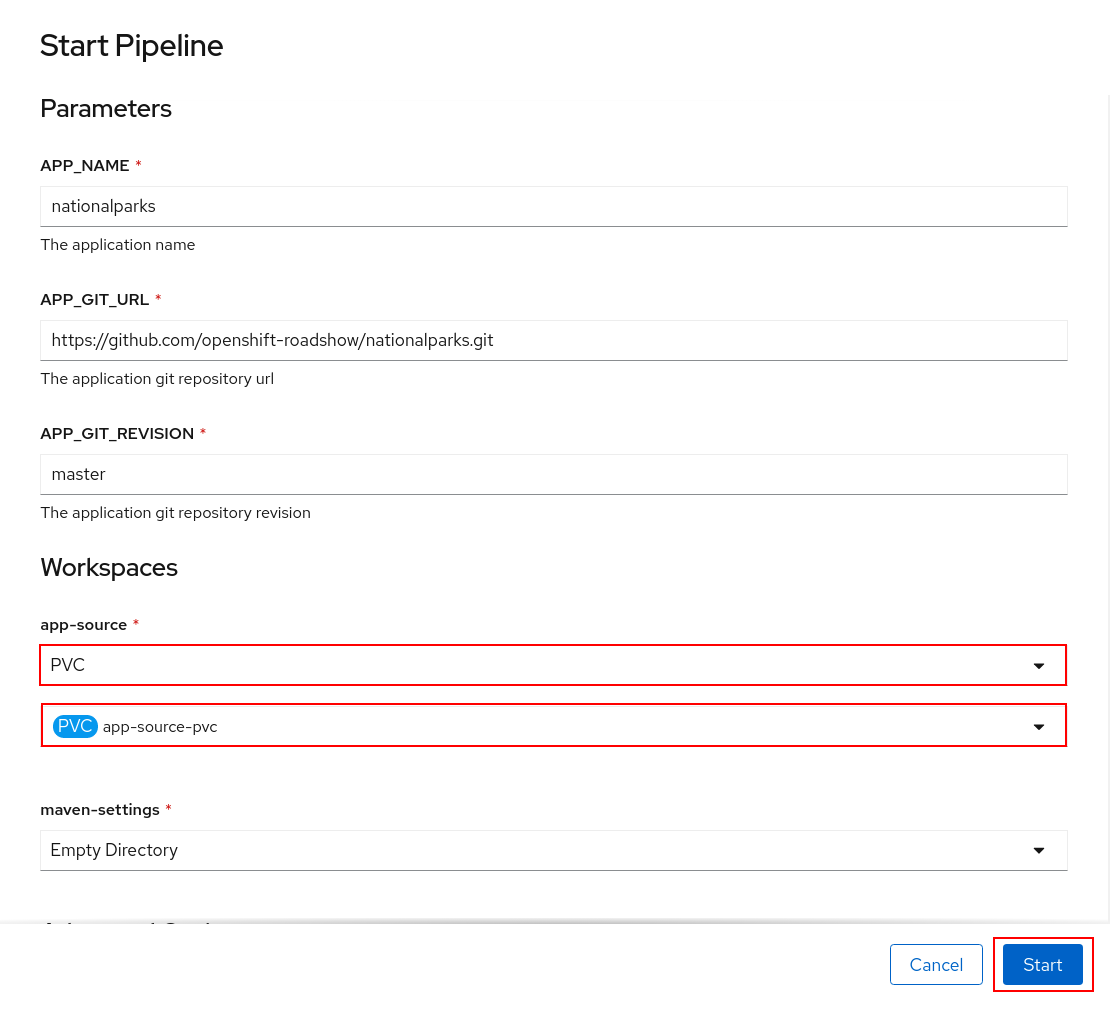
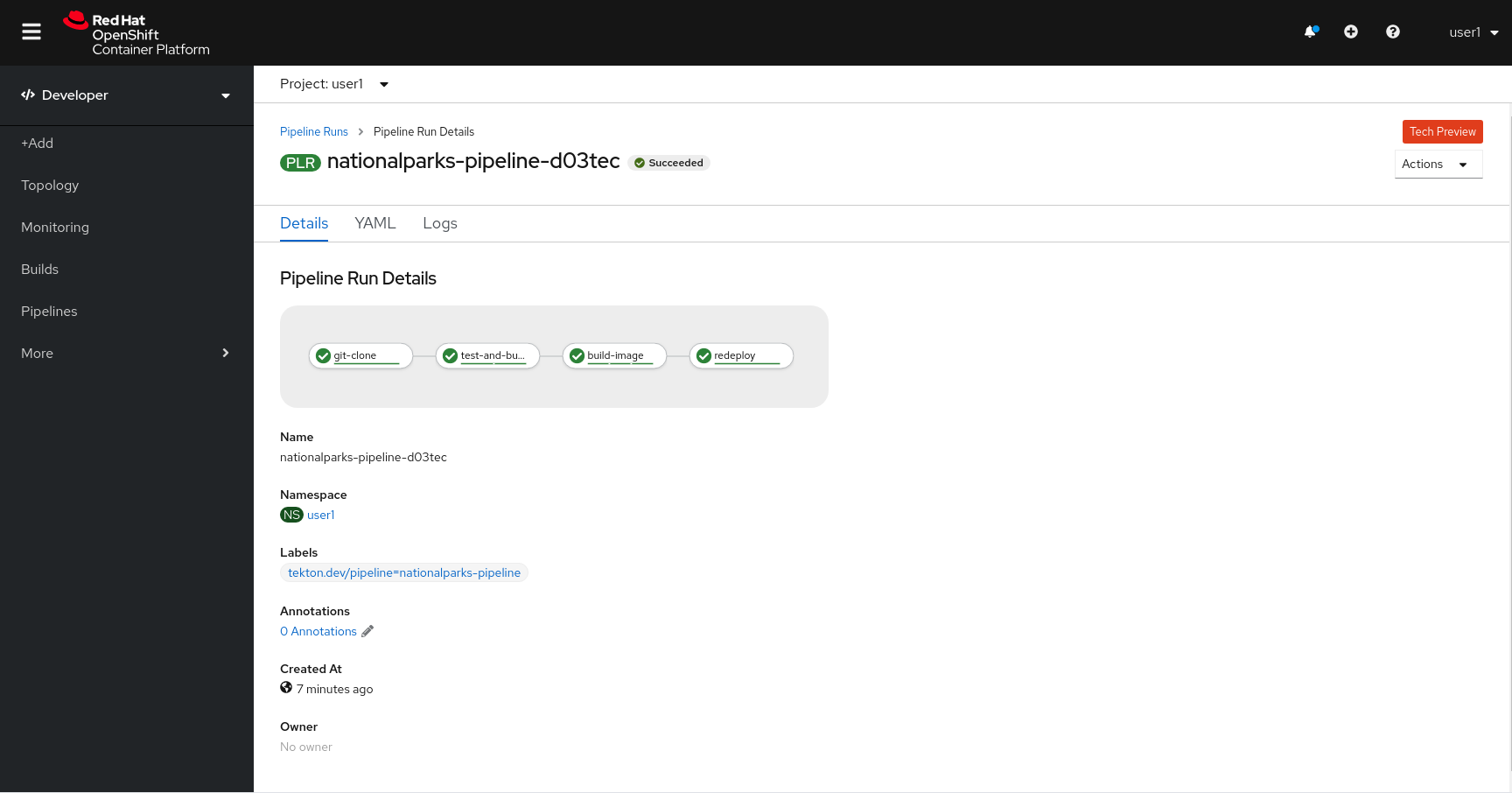
You can follow the Pipeline execution at ease from Web Console. Open Developer Perspective and go to left-side menu, click on Pipeline, then click on nationalparks-pipeline. Switch to Pipeline Runs tab to watch all the steps in progress:
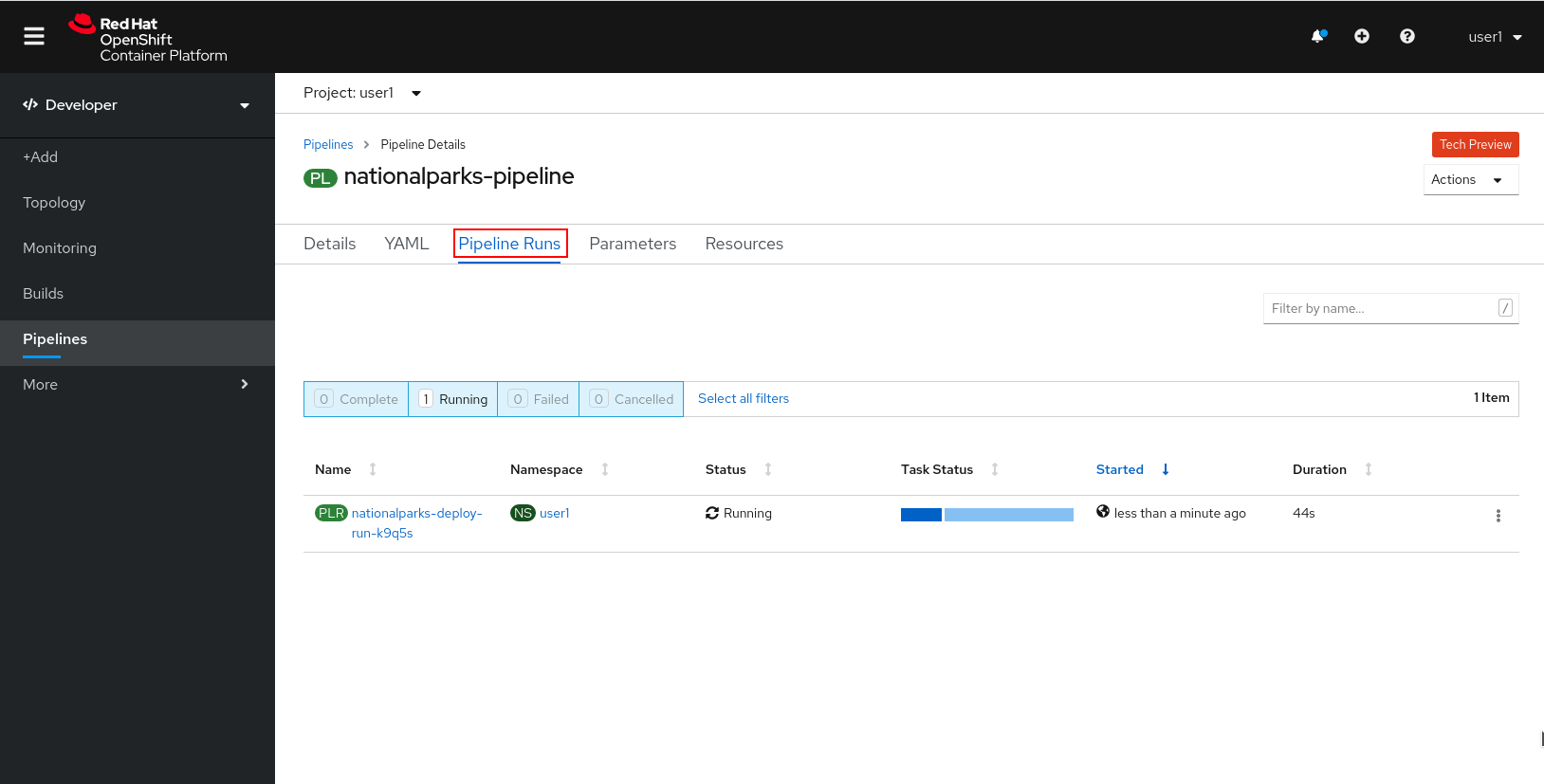
The click on the PipelineRun national-parks-deploy-run-:
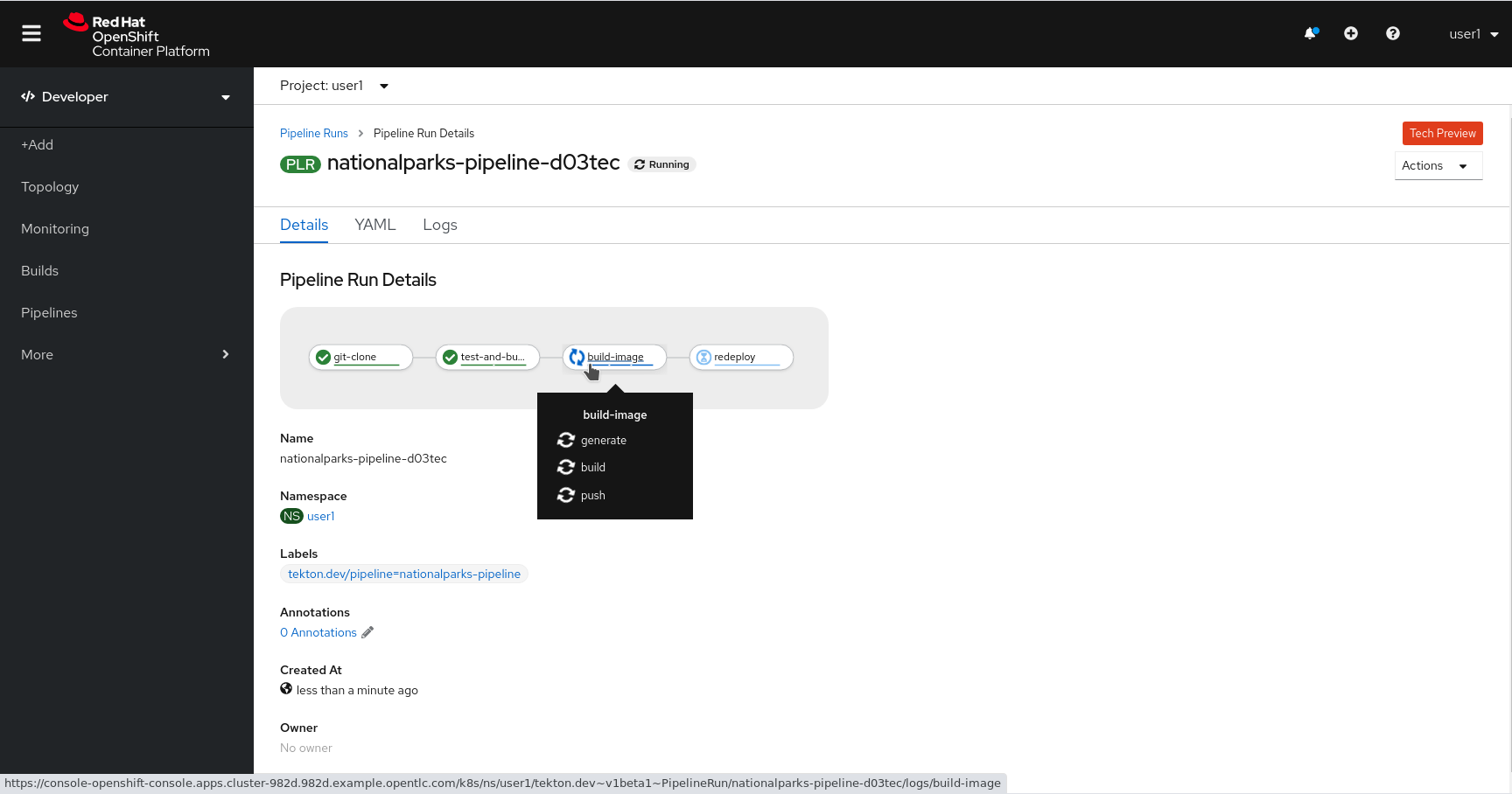
Then click on the Task running to check logs:
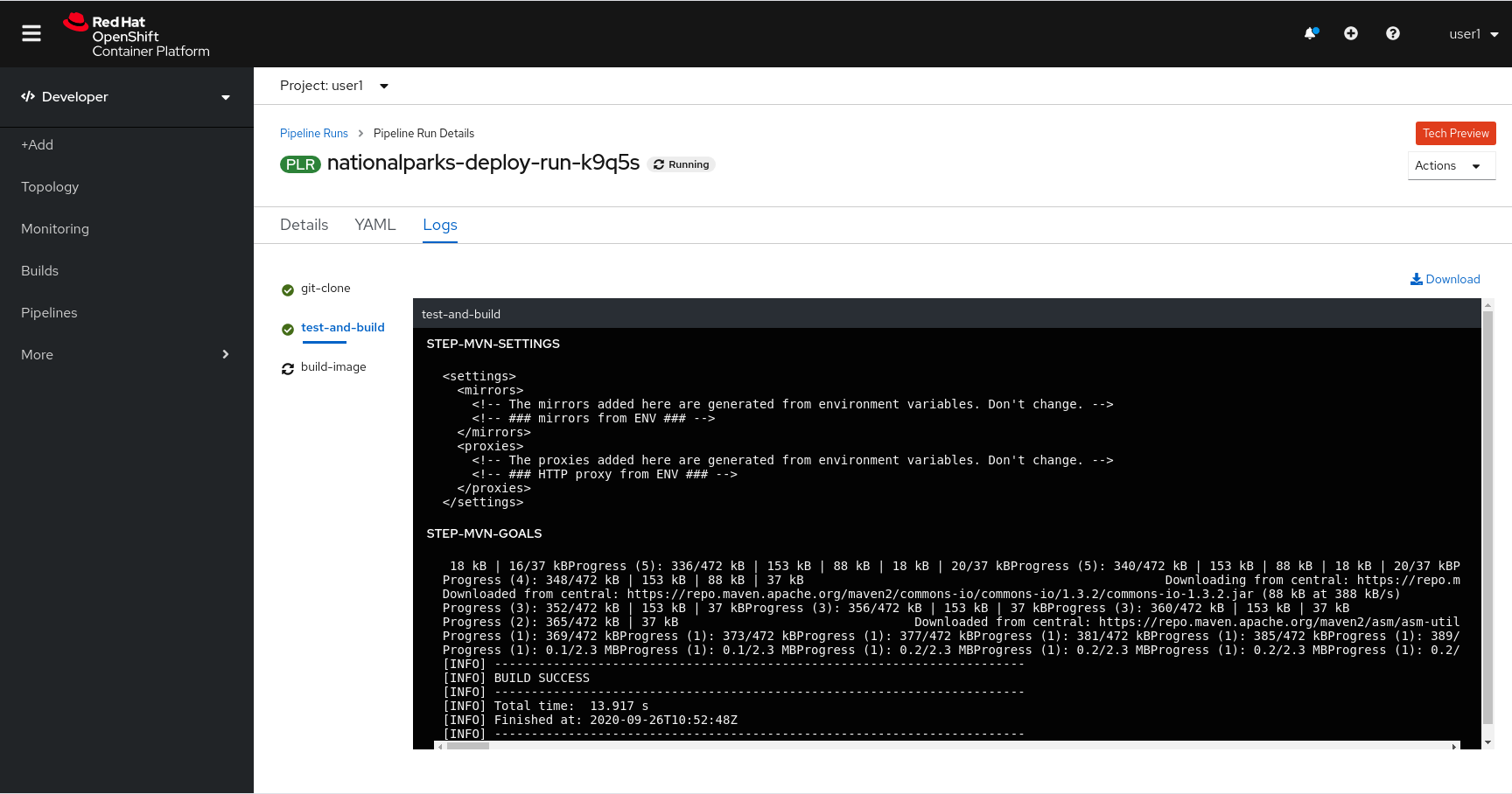
Verify PipelineRun has been completed with success: