Using the Kafka Streams API with OpenShift Streams for Apache Kafka
Learn how to use Kafka Streams API to create realtime data processing pipelines without having to install, configure, run, and maintain infrastructure.
Introduction to OpenShift Streams for Apache Kafka
Duration |
Audience |
Level |
1 hour |
Developers that want to create realtime data processing pipelines using Apache Kafka. |
Intermediate |
Kafka Streams provides a DSL (Domain Specific Language) that enables developers to create scalable data stream processing pipelines with minimal amounts of code. The DSL supports stateless operations such as filtering an existing topic to create a new topic containing records matching specific criteria. Stateful operations are also possible such as producing aggregates and joining records from multiple input streams.
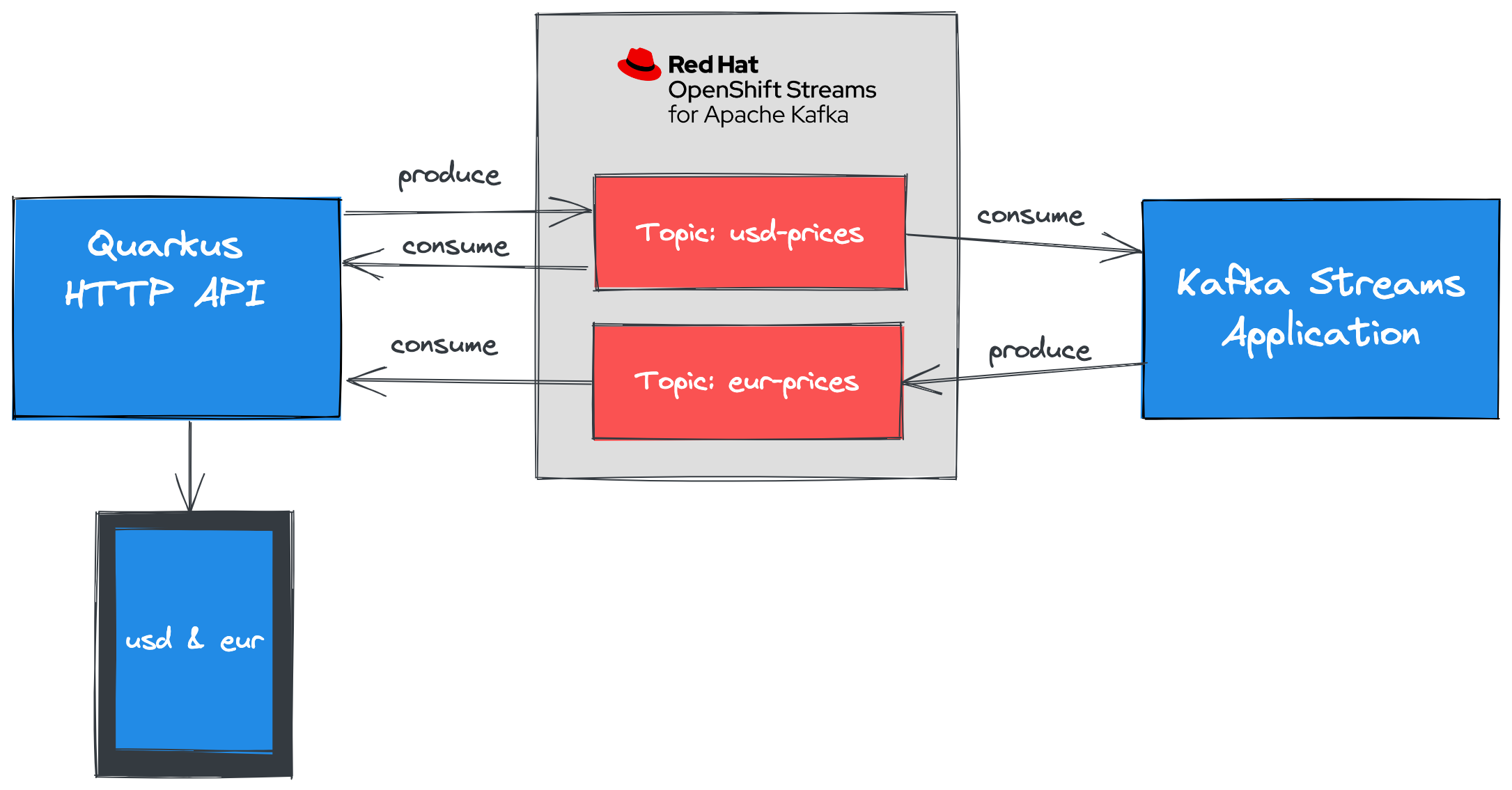
In this tutorial you will:
-
Create an instance of Red Hat OpenShift Streams for Apache Kafka.
-
Create a service account to connect to the Kafka instance.
-
Deploy a Quarkus application that produces records into the Kafka instance.
-
Develop an application that uses the Kafka Streams DSL to produce records from existing records.