Design Chaos experiments
2 MINUTE PRACTICE
What is Chaos Engineering?
Take an example where you have two services that communicate with each other.
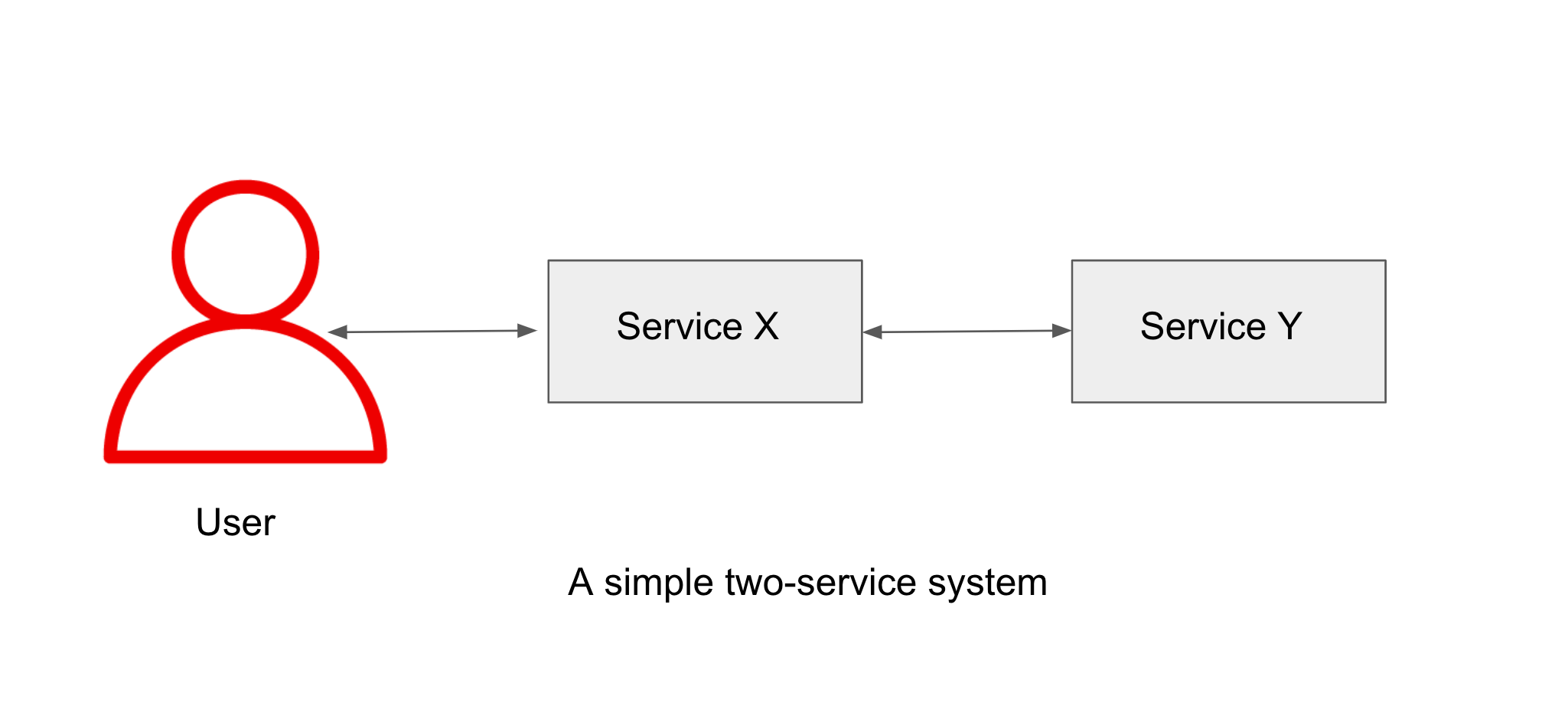
-
What should happen if Service Y dies ?
-
What will happen to Service X if Service Y starts responding slowly ?
-
What happens if Service Y comes back after going away for a period of time?
-
What happens if the connection between Service X and Service Y becomes increasingly busy ?
-
What happens if the CPU that is being used by Service Y is maxed out? and most importantly, what does this all mean to the user?
You might believe you’ve designed the services and the infrastructure perfectly to accomodate all of these cases, but how to you know ? Even in such a simple system it is likely there might be some surprises --some dark debt — present.
Chaos engineering provides a way of exploring these uncertainties to find out whether your assumptions of the system’s resiliency hold water in the real world.
Plan a Chaos Experiment
Chaos Engineering begins by asking the question :
"Do we know what the system might do in this case ?"
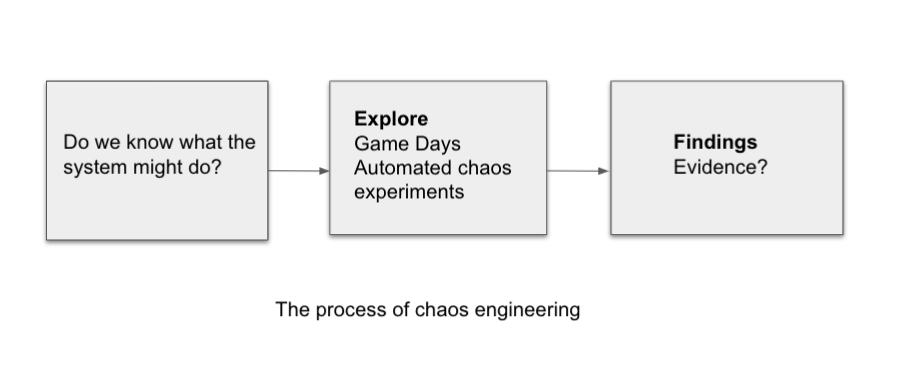
The general process for chaos engineering looks as follows:
-
Define a steady-state hypothesis: You need to start with an idea of what can go awry. Start with a failure to inject and predict an outcome for when it is running live.
-
Confirm the steady-state and simulate some real-world events: Perform tests using real-world scenarios to see how your system behaves under particular stress conditions or circumstances.
-
Confirm the steady-state again: We need to confirm what changes occurred, so checking it again gives us insights into system behavior.
-
Collect metrics and observe dashboards: You need to measure your system’s durability and availability. It is best practice to use key performance metrics that correlate with customer success or usage. We want to measure the failure against our hypothesis by looking at factors like impact on latency or requests per second.
-
Make changes and fix issues: After running an experiment, you should have a good idea of what is working and what needs to be altered. Now we can identify what will lead to an outage, and we know exactly what breaks the system. So, go fix it, and try again with a new experiment.
Later on this workshop we will use Openshift Service Mesh to inject failures in our Experiment .
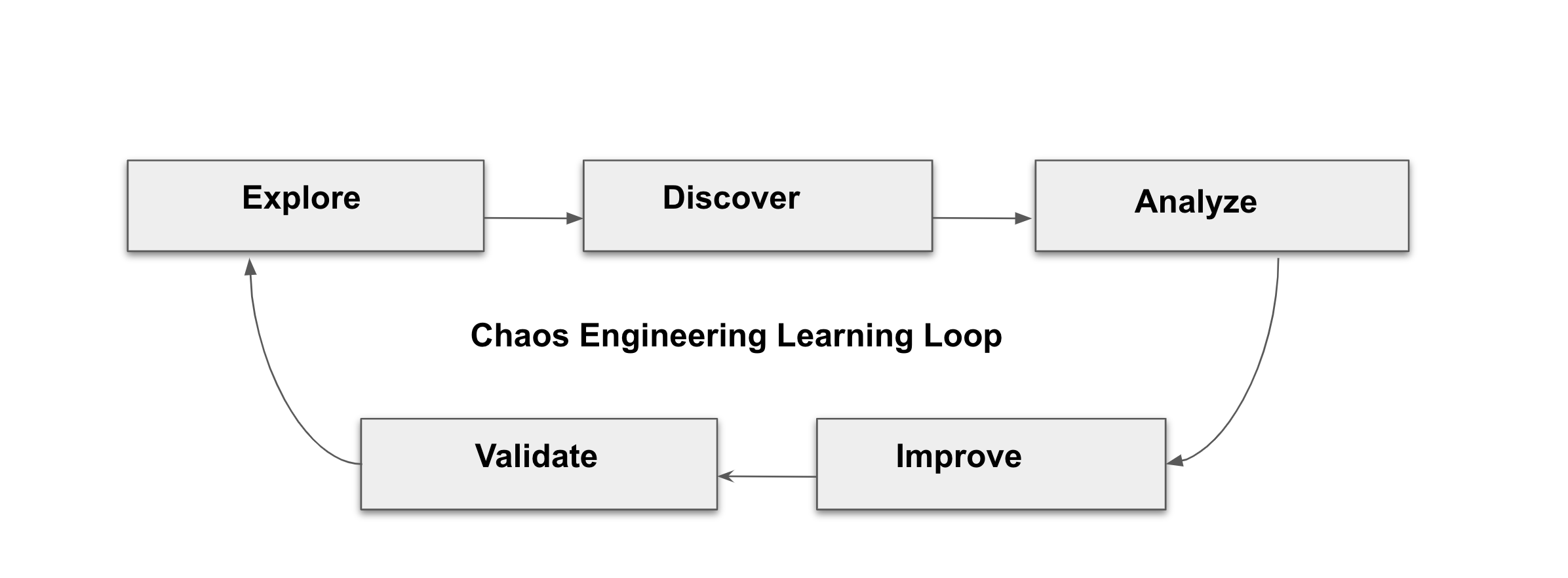
Following the Chaos Engineering Learning Loop the initial step is to Explore the target system, i.e our application, to attempt to surface or discover any weaknesses. The Experiments we will use are already written for you, using (5. Chaos Experiment 1: Network latency) and (6. Chaos Experiment 2: Unavailable Service).
Kiali and Openshift Developer Console (3. Explore the Application) will allow you to explore and to discover the application. Grafana (4. Define and monitor Chaos metrics is part of the Discovery of the application too.
When you will be ready to execute your experiment (5. Chaos Experiment 1: Network latency) and (6. Chaos Experiment 2: Unavailable Service) you will see how the target system is reacting. You will enter the discovery and analysis phases of the Chaos Engineering Learning Loop and after the analysis you will Improve and Validate the correction made.